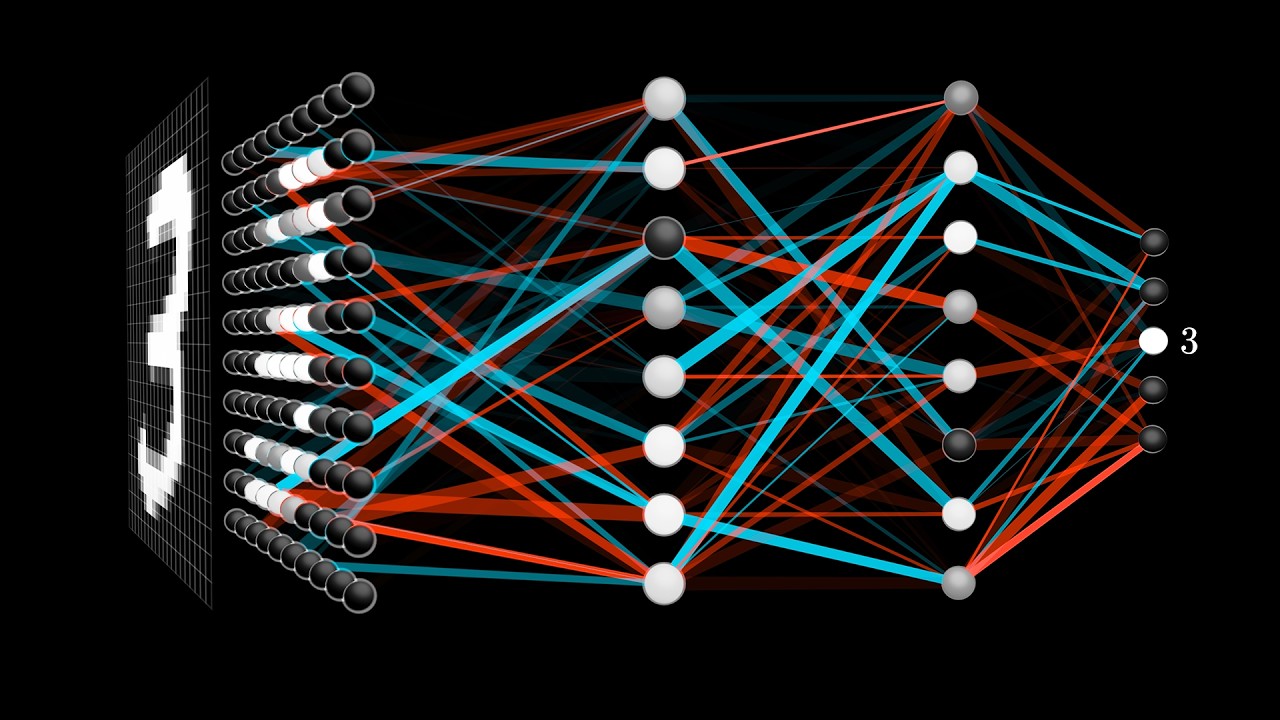
Come avrai notato dalla marea di articoli e spiegazioni che circolano, l’intelligenza artificiale è spesso percepita come una specie di magia. Ma tu mi segui, e sai che dietro c’è tecnologia; e dove c’è tecnologia, ci sono metodi.
Molti descrivono la tecnica del prompting come qualcosa di banale: digiti “fammi X” e l’AI risponde… Bello, vero? È quello che hai fatto finora? Se è così, sai bene che generando un testo da un prompt, il risultato cambia ogni volta, è impreciso, e serve tempo per trovare la formula giusta. Hanno anche inventato il termine “allucinazioni” per descrivere i “bug”.
Ma te (e ai tuoi futuri clienti) servono risultati coerenti, ripetibili e di qualità professionale, per questo motivo a maggio del 2025 ho spiegato più di 15 tecniche nel mio libro tradotto in 4 lingue (QUI).
Nella mia visione, la figura del “prompter” diventerà sempre più importante. Dunque, è fondamentale avere padronanza delle metodologie di interrogazione degli LLM: sarà certamente una delle competenze più richieste nel prossimo futuro.
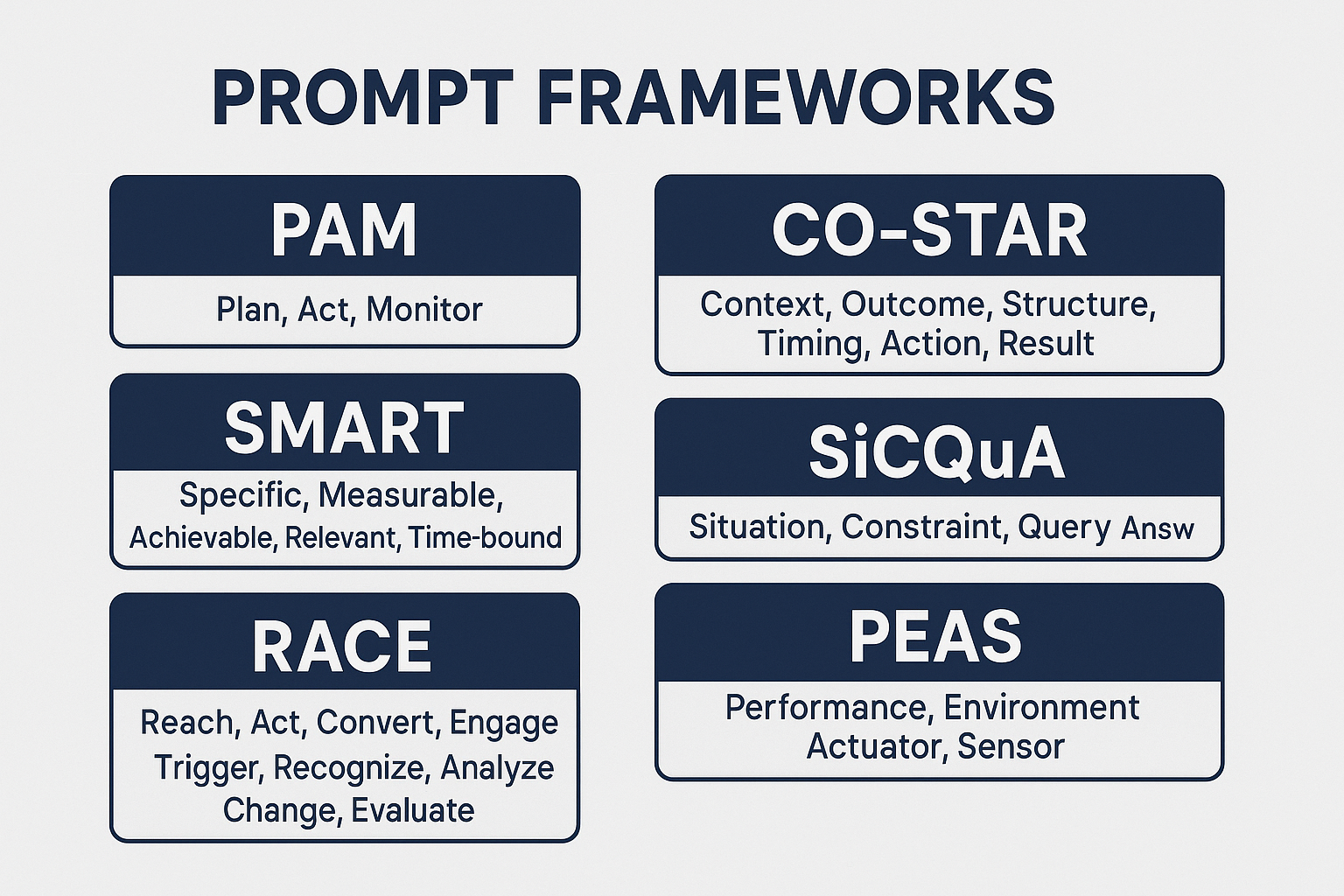
Oggi, a distanza di soli 6 mesi (che nel campo dell’IA equivalgono a un’epoca geologica), quelle tecniche sono state sintetizzate, o “compattate”, in sette veri e propri framework di prompt (tecniche/metodologie d’uso).
In questo articolo ti accompagnerò passo passo, usando un unico esempio che complicheremo gradualmente, man mano che saliamo di livello.
Caso unico per tutti gli esempi
Scrivere una scheda prodotto per e-commerce del “Kit serratura baule Vespa (cod. 299676)”.
Obiettivo: testo chiaro, orientato alla vendita, con compatibilità e CTA.
PAM > Action > Monitor
Quando usarlo: è il più semplice, usalo per iniziare subito e migliorare un output grezzo. In pratica iteri più volte fino ad arrivare all’obiettivo.
Prompt > (leggi la risposta) > Monitor/Modify: [cosa cambi e perché]
Esempio 1
Prompt v1: “Scrivi una scheda prodotto per il kit serratura baule Vespa 299676.”
Modify: “Riduci a 120–150 parole e inserisci una CTA finale.”
Perché funziona: ti fa iterare subito, senza teoria, ma il risultato può essere abbastanza deludente.
Stiamo usando una AI, proviamo a chiedergli qualcosa in più:
SMART — Specific, Measurable, Achievable, Relevant, Time-bound
Quando usarlo: per definire criteri misurabili e dire con chiarezza quando il testo è completo.
Obiettivo SMART: [S][M][A][R][T] + criteri di accettazione
Esempio 2
Obiettivo SMART: 120–150 parole, leggibilità ≥60 (Flesch IT),
1 riga di beneficio iniziale, 3 bullet (compatibilità, installazione, garanzia), chiusura con CTA unica (“Aggiungi al carrello”).
RACE — Role, Action, Context, Execute
Quando usarlo: per dare ruolo, compito, contesto e formato.
Effetto: cala la variabilità di tono e struttura.
Role: [chi sei]
Action: [cosa devi fare]
Context: [per chi, vincoli, USP]
Execute: [formato, stile, lunghezza]
Esempio 3
Role: Copywriter e-commerce aftermarket scooter.
Action: Scrivi la scheda prodotto del kit serratura baule Vespa 299676.
Context: Target fai-da-te; evidenzia compatibilità e installazione semplice.
Execute: 120–150 parole; apertura con beneficio; 3 bullet (compatibilità, installazione, garanzia);
chiusura con CTA “Aggiungi al carrello”.
TRACE — Task, Role, Audience, Context, Example
Quando usarlo: quando il pubblico conta e vuoi un esempio guida per allineare stile e lessico.
Task: [output]
Role: [persona]
Audience: [per chi]
Context: [scenario, vincoli]
Example: [mini-esempio di tono/struttura]
Esempio 4
Task: Scheda prodotto e-commerce.
Role: Copywriter tecnico.
Audience: Proprietari Vespa ET2/ET4/Liberty senza esperienza meccanica.
Context: Ricambio originale, modelli compatibili, istruzioni base.
Example (tono): “Compatibile con Vespa ET2/ET4. Si installa in pochi minuti con gli attrezzi di base. Garanzia 24 mesi.”
CO-STAR — Context, Objective, Style, Tone, Audience, Response
Quando usarlo: quando, oltre al contenuto, vuoi anche che il testo abbia dei precisi stili e toni.
Context > Objective > Style > Tone > Audience > Response (formato)
Esempio 5
Context: Scheda prodotto per e-commerce ricambi.
Objective: Massimizzare chiarezza e conversione.
Style: Frasi brevi, scannable, lessico semplice.
Tone: Affidabile, pratico, zero iperboli.
Audience: Proprietari Vespa senza esperienza tecnica.
Response: 1 paragrafo 120–150 parole + 3 bullet + CTA finale.
SiCQuA — Situation, Complication, Question, Answer
Quando usarlo: per strutturare una micro-narrazione che sciolga i dubbi del cliente.
Situazione
Complicazione
Q-domanda
Azione (risposta)
Esempio 6
Situation: Chi cerca ricambi Vespa vuole compatibilità certa.
Complication: Modelli/anni generano confusione.
Question: Questo kit serratura 299676 è giusto per me?
Answer: Elenca modelli compatibili (ET2, ET4, Liberty…), spiega installazione base,
ricorda garanzia/resi, chiudi con CTA.
PEAS — Performance, Environment, Actuators, Sensors
E’ il più tecnico dei framework, usalo quando devi progettare un agente/pipeline che generi e validi la scheda.
Performance: [metriche/SLAs]
Environment: [dove opera, vincoli]
Actuators (Output): [cosa produce]
Sensors (Input): [quali dati/fonti usa]
+ Failure modes & Fallback
Esempio 7
Performance: 100% nomi modello validi; ≤2 errori ortografici; leggibilità ≥60.
Environment: Catalogo interno + DB compatibilità; privacy GDPR.
Actuators: Blocco HTML scheda prodotto + JSON compatibilità.
Sensors: SKU 299676, lista modelli, manuale tecnico.
Failure & Fallback: se compatibilità mancante → chiedi conferma; se conflitti → mostra alert.
Da grezzo a pro: lo stesso prompt che “cresce”
Ok, se prima di questo articolo non eri un prompter professionista 😉 adesso sai che un prompt non è una frase “magica”: è progettazione.
Parti da PAM, aggiungi SMART per definire cosa significa “buono”, struttura con RACE.
Quando serve coerenza di brand e audience, passa a TRACE/CO-STAR. Se devi educare e convincere, usa SiCQuA. E quando vuoi scalare con affidabilità, modella il sistema con PEAS.
Ecco gli esempi pratici:
PAM → SMART
PAM v1: Scrivi una scheda prodotto per kit serratura baule Vespa 299676.
Modify: 120–150 parole, 3 bullet (compatibilità, installazione, garanzia), CTA finale.
SMART: Leggibilità ≥60; evita superlativi generici; niente termini tecnici non spiegati.
RACE → TRACE → CO-STAR
RACE: Role (copy e-commerce) + Action (scheda) + Context (target fai-da-te) + Execute (formato).
TRACE: aggiungi Audience (ET2/ET4/Liberty) + Example (tono pratico).
CO-STAR: separa Objective (conversione) da Style/Tone (chiaro, affidabile) e Response (formato).
SCQA → PEAS
SCQA: incornicia i dubbi (“è compatibile con il mio modello?”) e rispondi in ordine logico.
PEAS: progetti l’agente che pesca i dati, valida la compatibilità e genera l’HTML finale.
Checklist (copia e incolla)
- PAM: prova → leggi → modifica una cosa alla volta.
- SMART: aggiungi 2–3 metriche verificabili.
- RACE: ruolo chiaro + compito + contesto + formato.
- TRACE: dichiara il pubblico e metti un mini-esempio.
- CO-STAR: separa obiettivo da stile/tono; definisci il formato di risposta.
- SiCQuA: situazione → problema → domanda → risposta/azioni.
- PEAS: metriche, input/output, errori previsti, fallback.